Pandas DataFrame count()
import pandas as pd
my_dict={'NAME':['Ravi','Raju','Alex','Ron','King','Jack'],
'ID':[1,2,3,4,5,6],
'MATH':[80,40,70,70,70,30],
'ENGLISH':[80,70,40,50,60,30]}
my_data = pd.DataFrame(data=my_dict)
print(my_data.count())NAME 6
ID 6
MATH 6
ENGLISH 6Using axis
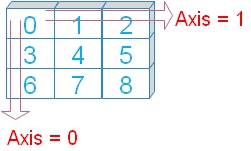 We will use option axis=0 ( default ) by adding to above code.
We will use option axis=0 ( default ) by adding to above code.( The last line is only changed )
print(my_data.count(axis=0))NAME 6
ID 6
MATH 6
ENGLISH 6print(my_data.count(axis=1))0 4
1 4
2 4
3 4
4 4
5 4import numpy as np
import pandas as pd
my_dict={'NAME':['Ravi','Raju','Alex','Ron','King','Jack'],
'ID':[1,2,3,4,5,6],
'MATH':[80,40,70,70,70,30],
'ENGLISH':[80,70,np.nan,50,60,30]}
my_data = pd.DataFrame(data=my_dict)
print(my_data.count(axis=1))0 4
1 4
2 3
3 4
4 4
5 4lavel option
We can specify the level option and get the dataimport numpy as np
import pandas as pd
my_dict={'NAME':['Ravi','Raju','Alex','Ron','King','Jack'],
'ID':[1,2,3,4,5,6],
'MATH':[80,40,70,70,70,30],
'ENGLISH':[80,70,np.nan,50,60,30]}
my_data = pd.DataFrame(data=my_dict)
my_data.set_index(['NAME','ID']).count(level='NAME') MATH ENGLISH
NAME
Alex 1 0
Jack 1 1
King 1 1
Raju 1 1
Ravi 1 1
Ron 1 1
Subhendu Mohapatra
Author
🎥 Join me live on YouTubePassionate about coding and teaching, I publish practical tutorials on PHP, Python, JavaScript, SQL, and web development. My goal is to make learning simple, engaging, and project‑oriented with real examples and source code.
Subscribe to our YouTube Channel here
This article is written by plus2net.com team.
https://www.plus2net.com

 Python Video Tutorials
Python Video Tutorials