Pandas : Python Data analysis tool.
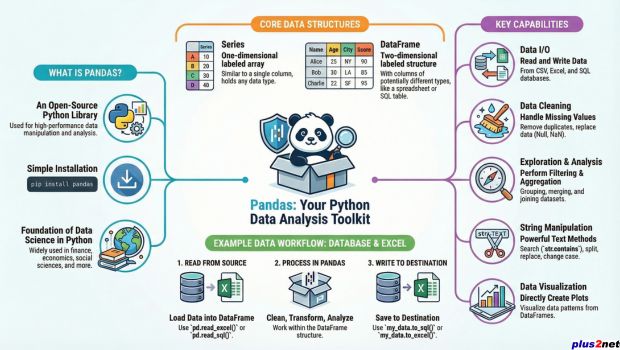
Pandas is a popular open-source Python library used for data manipulation and analysis. It provides powerful tools for working with structured data, including the ability to read and write data from various file formats such as CSV, Excel, SQL databases, and more.
What it can do
Pandas allows users to perform data wrangling tasks, such as filtering, cleaning, transforming, merging, and reshaping data. It provides two main data structures:1. Series, which is a one-dimensional labeled array that can hold any data type,
Pandas Series
2. DataFrame, which is a two-dimensional labeled data structure with columns of potentially different data types.
Pandas DataFrame Atributes Methods
Where Pandas is used
Pandas is widely used in data science, finance, economics, social sciences, and many other fields where data analysis and manipulation are required. It is also integrated with other Python libraries such as NumPy, Matplotlib, and Scikit-learn to provide a complete data analysis ecosystem in Python.How to install Python Pandas library
pip install pandasimport pandas as pd
print("Pandas Version : ",pd.__version__)pip install --upgrade pandasData Exploration and Analysis
Data statistics, filtering, Aggregation and grouping, data merging and joining etc.
Data AnalysisData Cleaning
Handling Null, NaN data, finding duplicate data, replacing data and more .
Data Cleaning
Five important basic Pandas DataFrame functions info(), head(), tail(), shape,size,ndim, columns
Creating Pandas DataFrame by using Numpy ndarray
validate_email
DataFrame Style
Pandas Date & Time
Exercises
| Exercise1 | Basic data handling , DataFrame |
| Exercise1-1 | Using cut(), groupby and plotting graphs |
| Exercise-Adv | Using groupby and merge of DataFrame |
| Exercise2 | Using str.contains(), max(), min(),len() of DataFrame |
| Exercise3 | Using date and time functions with groupby of DataFrame |
| Exercise3-2 | Using date and time functions of DataFrame |
| Exercise3-3 | Using date and time functions with groupby |
| Exercise3-4 | Using date and time with where timedelta64 |
I/O : Input and output Data from Pandas ( Excel , MySQL , JSon)
 We can’t store data in Pandas DataFrame. We can process the data by using Pandas DataFrame after reading data from different sources. Similarly after processing we can save data in different files or database by using available tools.
We can’t store data in Pandas DataFrame. We can process the data by using Pandas DataFrame after reading data from different sources. Similarly after processing we can save data in different files or database by using available tools.
Data input and output from Pandas DataFrame
Filtering records
| loc | Values at different position using column label |
| rows | Filtering rows based on data |
handling string using str methods
| str.contains | string matching against data columns |
| str.contains.sum | Max Min Sum of any column |
| Convert Case | Lower to Upper and vice versa |
| split() | Breaking string using delimiter |
| slice() | Substring by breaking string |
| cat() | Concatenate strings |
| count() | Number of occurrences of pattern |
| replace() | Replace part of string by regex |
| len() | Length of the data in our DataFrame |
| zfill() | Prepending string with '0' |
| Pandas Date and time | Managing Date and time in Pandas DataFrame |
Excel to MySQL
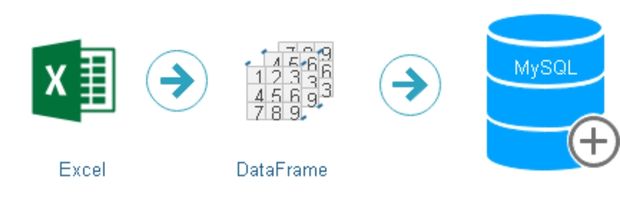
import pandas as pd
my_data = pd.read_excel('D:\emp.xlsx')
# reading data from root of D drive.
from sqlalchemy import create_engine
my_conn = create_engine("mysql+mysqldb://userid:password@localhost/database_name")
### Creating new table emp or appending existing table
my_data.to_sql(con=my_conn,name='emp',if_exists='append')MySQL to Excel

import pandas as pd
from sqlalchemy import create_engine
my_conn = create_engine("mysql+mysqldb://userid:password@localhost/database_name")
sql="SELECT * FROM emp "
my_data = pd.read_sql(sql,my_conn )
my_data.to_excel('D:\emp2.xlsx')Columns and rows
| columns | List of column headers of a DataFrame |
| rename | rename columns of DataFrame |
| add_suffix | adding suffix to column names of a DataFrame |
| add_prefix | adding prefix to column names of a DataFrame |
| drop | Delete columns or rows |
import pandas as pd
print(len(dir(pd))) # 139for i in dir(pd):
print(i)Parameters of functions
There are some common parameters used in Pandas functions. Understanding them will help in quick learning of functionality.| inplace | Boolean ( True / False ), Result is written back to same dataframe ( True ). The source dataframe is changed. False otherwise. |
Upload Excel or CSV file in google drive and connect from Colab Python platform using mount drive
Pandas and Tkinter
Integrating Pandas with Tkinter involves using Pandas to read and manipulate data, and then displaying that data using Tkinter widgets such as labels, tables, and plots.Projects using Tkinter
Download files of our Video Tutorials
| Section | Details | Download |
|---|---|---|
| A | Introduction | Download |

Subhendu Mohapatra
Author
🎥 Join me live on YouTubePassionate about coding and teaching, I publish practical tutorials on PHP, Python, JavaScript, SQL, and web development. My goal is to make learning simple, engaging, and project‑oriented with real examples and source code.
Subscribe to our YouTube Channel here
This article is written by plus2net.com team.
https://www.plus2net.com

 Python Video Tutorials
Python Video Tutorials