os operating system interfaces module
| Functions | Details |
|---|---|
| mkdir() | Create directory |
| walk() | path, directories and files of sub -directories |
- Getting the os name
- Current working directory
- Change directory
- Directory Listing by listdir()
- expanduser
- Checking Path
- isdir()
- splitext()
- Get file creation and file modification date and time
- File size
- File Modified date, file extension and file size
- OSError
- remove() : Deleting file
- Printing to printer
- Printing PDF file
- Checking links in all pages of a directory
- Check presence of string inside all files of a directory
- List the file if string is not present inside the file
- All files with details of a directory in Excel
Getting the os name 🔝
Name of the operating system.import os
print(os.name) # nt Current working directory 🔝
print(os.getcwd()) # c:\Users\DellHPimport os
print(os.path.dirname(os.path.abspath(__file__)))import csv
import os
file_name=os.path.dirname(os.path.abspath(__file__))+'/student.csv'
#print(os.getcwd())
#print(os.path.dirname(os.path.abspath(__file__)))
if not os.path.exists(file_name):
with open(file_name, mode='w', newline='') as file:
writer = csv.writer(file)
writer.writerow(["id", "name", "class", "mark", "gender"])Change directory 🔝
import os
print(os.getcwd()) # c:\Users\DellHP
path='D:\\my_dir'
os.chdir(path)
print(os.getcwd()) # D:\my_diros.chdir('..')Directory Listing by listdir() 🔝
Returns a list of directories and files of given path. If input path is not given then a list of files and directories of current working directory is returned.import os
path = "E:\\testing\\images\\" # Directory Path
print(os.listdir(path))expanduser 🔝
Users home directoryimport os
print(os.path.expanduser('~\\test.txt'))C:\Users\HP\test.txtChecking Path 🔝
Return True if path or open file description is avilable. Return False otherwise.import os
path = "E:\\testing\\images\\" # Directory Path
print(os.path.exists(path)) # Trueimport os
path = "E:\\testing\\images\\test3.png" # file path
print(os.path.exists(path)) # Trueisdir() 🔝
Returns True for directory.import os
path = "E:\\testing\\images\\test3.png" # File Path
print(os.path.isdir(path)) # False
path = "E:\\testing\\images\\" # Directory Path
print(os.path.isdir(path)) # True
splitext() 🔝
Split the path into a pair. path=root + extimport os
path = "E:\\testing\\images\\test3.png" # Path
print(os.path.splitext(path)) # ('E:\\testing\\images\\test3', '.png')
print(os.path.splitext(path)[0]) #E:\testing\images\test3
print(os.path.splitext(path)[1]) #.pngGet file creation and file modification date and time 🔝
Use strftime() to get different date and time format output. Here getmtime() returns the file modified timestamp and getctime() returns file creation timestamp.import os
from datetime import datetime
path = "E:\\testing\\images\\test3.png" # Directory Path
t_stamp=os.path.getmtime(path) # for file modificaton time
#t_stamp=os.path.getctime(path) # for file Creation time
dt_mod = datetime.fromtimestamp(t_stamp) # date object
print('File Modified on:', dt_mod) # Printing date and time
m_date = datetime.strftime(dt_mod, '%Y-%m-%d') # Change format
print(m_date)File size 🔝
In below code we can include this line with getsize() to get the file size in bytes.size=os.path.getsize(path+f)File Modified date, file extension and file size 🔝
Collecting all files with details from the input directory and creating DataFrame Part II
import os
from datetime import datetime
#path = "E:\\testing\\images\\test3.png" # Directory Path
path = "E:\\testing\\" # Directory Path
files=os.listdir(path)
for f in files:
t_stamp=os.path.getmtime(path+f) # for file modificaton time
#t_stamp=os.path.getctime(path) # for file Creation time
f_name,f_extension=os.path.splitext(path+f)
size=os.path.getsize(path+f)
dt_mod = datetime.fromtimestamp(t_stamp) # date object
#print('File Modified on:', dt_mod) # Prting date and time
m_date = datetime.strftime(dt_mod, '%Y-%m-%d') # Change format
print(f, f_extension, m_date,size)OSError 🔝
While using above functions, for any system related errors we will get OSError. We can use try except error handling to display message saying error details. Here is a code to raise error while deleting directories.import os
path='D:\\my_dir1\\my_dir2\\my_dir3\\my_dir4'
#os.makedirs(path) # create all directories in the path
try:
os.rmdir(path) # delete directory my_dir4
except OSError as e:
print(e) # Specific error message
print ("Failed to delete %s " % path)
else:
print ("Successfully deleted the directory %s " % path)[WinError 2] The system cannot find the file specified: 'D:\\my_dir1\\my_dir2\\my_dir3\\my_dir4'
Failed to delete D:\my_dir1\my_dir2\my_dir3\my_dir4 remove() : Deleting file 🔝
Using file path we can delete the file by using remove()import os
path='D:\\testing\\my_db\\my_db.db' # update your path
try:
os.remove(path) # delete directory my_dir4
except OSError as e:
print(e) # Specific error message
print ("Failed to delete %s " % path)
else:
print ("Successfully deleted the file %s " % path)Printing to printer 🔝
import os
path = "E:\\testing\\images\\test.txt" # path to file.
os.startfile(path, "print")Printing PDF file 🔝
Install these librariesimport win32api
import win32print
# A List containing the system printers
all_printers = [printer[2] for printer in win32print.EnumPrinters(2)]
# Update the default printer or ask user to select.
win32print.SetDefaultPrinter(all_printers[2]) # Update your printers
path2 = "F:\\testing\\images\\certificate_12.pdf" # Path of PDF file
win32api.ShellExecute(0, "print", path2, None, ".", 0)Checking links in all pages of a directory 🔝
import re,os
file_name_to_check='pb-check-demo.php'
path1='C:/xampp/htdocs/example/dir_name/' # dir path
file_list=os.listdir(path1)
if(file_name_to_check in file_list):
print('File is there, checking')
for f in file_list:
if(os.path.getsize(path1+f)>500):
filename,file_extension=os.path.splitext(path1+f)
if(file_extension=='.php'): # check this extension only
fob= open(path1+f,'r',encoding='utf8',errors='ignore')
data=fob.read() # collect data
fob.close() # close file object
urls1 = re.findall(r'href=[\'"]?([^\'" >]+)', data,re.IGNORECASE)
if(file_name_to_check in urls1):
print(f)
else:
print('File is not there, check the name and then submit. ')Check presence of string inside all files of a directory 🔝
Inside the directory check for file names having tkinter and inside the file not having the string www.youtube.We can use regular expression or find() to search for strings.
import re,os
path1='C:/xampp/htdocs/dir_name/python/' # dir path
file_list=os.listdir(path1) # List of files
for f in file_list:
#if re.search('tkinter',f, re.IGNORECASE):
if f.lower().find('tkinter')>=0: # check string in file name
#print(f)
fob= open(path1+f,'r',encoding='utf8',errors='ignore')
data=fob.read().lower() # collect data
fob.close() # close file object
if data.find('www.youtube')<0: # not present
print(f)List the file if string is not present inside the file 🔝
import re,os
path1='C:/xampp/htdocs/dir_name/python/' # dir path
file_list=os.listdir(path1) # List of files
total=0
for f in file_list:
#if re.search('tkinter',f, re.IGNORECASE):
#if f.lower().find('tkinter')>=0: # check string in file name
#print(f)
if(os.path.getsize(path1+f)>500):
filename,file_extension=os.path.splitext(path1+f)
if(file_extension=='.php'): # check this extension only
fob= open(path1+f,'r',encoding='utf8',errors='ignore')
data=fob.read().lower() # collect data
fob.close() # close file object
#if data.find('www.youtube')<0: # not present
if data.find('breadcrumb')<0: # not present
print(f)
total=total+1
print("Total files : ",len(file_list),", Not having string : ",total)Replace this line
if(file_extension=='.php'): # check this extension only if (
file_extension == '.php'
and not f.startswith('link-')
and not f.startswith('top-link-')
):All files with details of a directory in Excel 🔝
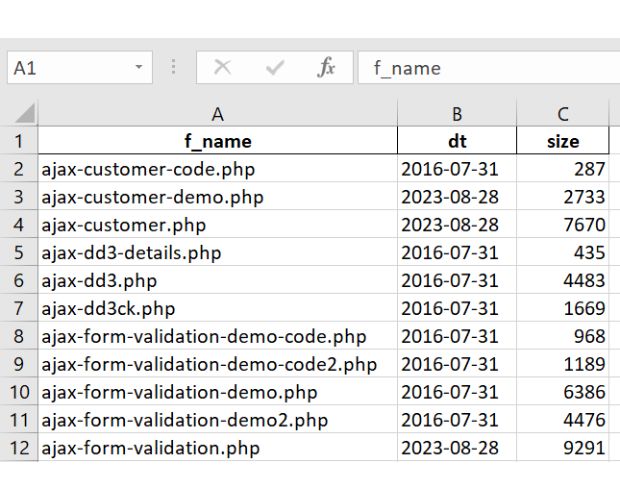
This code example demonstrates how to use the `os` module in Python to get a list of all files in a directory, along with their details such as file size, creation time or modification time. This information can be useful for various tasks such as file management, data analysis, and system administration.
The code uses the
os.listdir() function to get a list of all files in the specified directory. It then uses a for loop to iterate through the list of files and retrieve their details.
We are using one list of directories and against each directory we are creating one excel file.
import os
from datetime import datetime
import pandas as pd
# source directory list to get list of files inside the directory
l1=['javascript_tutorial','php_tutorial','html_tutorial','sql_tutorial','python']
for d in l1:
path = "C:\\xampp\\htdocs\\plus2net\\"+d+"\\" # full path to directory
f_x='C:\\data2\\'+d+'.xlsx' #path with name, to store final excel file for directory
files=os.listdir(path) # List of files in the directory
df = pd.DataFrame(columns = ['f_name', 'dt', 'size']) #create blank DataFrame
df['dt'] = pd.to_datetime(df['dt']) # change to date column
for f in files: # list of files looping
f_name,f_extension=os.path.splitext(path+f)
if(f_extension=='.php'): # To check only .php file extensions
size=os.path.getsize(path+f)
t_stamp=os.path.getmtime(path+f) # for file modificaton time
#t_stamp=os.path.getctime(path) # for file Creation time
dt_mod = datetime.fromtimestamp(t_stamp) # date object
#print('File Modified on:', dt_mod) # Prting date and time
m_date = datetime.strftime(dt_mod, '%Y-%m-%d') # Change format
#print(f, f_extension, m_date,size)
df2 = pd.DataFrame({'f_name': [f], 'dt': [m_date],'size':[size]})
df=pd.concat([df,df2]) # add row to DataFrame
#df = df.append({'f_name' : f, 'dt' : m_date, 'size' : size},ignore_index = True)
#print(df.head())
df.to_excel(f_x,index=False) # create excel file with file dataUsing the above data we can check the Canonical tag by using BeautifulSoup
Creating Sitemap xml file from a directory
Reading Sitemap xml file and fetching details to store
In place of Pandas to_excel() we can use to_csv() to create csv file.
Pandas to_sql() to create database table using the DataFrame
Using the above Excel file or Database table we can create site map in xml format.

Subhendu Mohapatra
Author
🎥 Join me live on YouTubePassionate about coding and teaching, I publish practical tutorials on PHP, Python, JavaScript, SQL, and web development. My goal is to make learning simple, engaging, and project‑oriented with real examples and source code.
Subscribe to our YouTube Channel here
This article is written by plus2net.com team.
https://www.plus2net.com

 Python Video Tutorials
Python Video Tutorials