to_excel(): DataFrame to Excel
import pandas as pd
my_dict={
'NAME':['Ravi','Raju','Alex'],
'ID':[1,2,3],'MATH':[30,40,50],
'ENGLISH':[20,30,40]
}
df = pd.DataFrame(data=my_dict) # DataFrame from dictionary
df.to_excel('D:\my_file.xlsx') # create Excel file
to_excel(): Data from Pandas DataFrame to Excel file #B02
Options
index: bool, default=True
By default pandas will add one index column. We can remove index by using option index=Falsedf.to_excel('D:\my_file.xlsx',index=False)Storing Path
We can keep in D drive ( root )df.to_excel('D:\my_file.xlsx')df.to_excel('D:\data\my_file.xlsx')na_rep Blank data
How to handle if data is blank, we can use na_rep='*'df.to_excel('D:\my_file.xlsx',na_rep='*')columns
List of columns to use while creating Excel file. Use only id and name columns heredf2.to_excel('C:\\data\\student2.xlsx', columns=['id','name'])header
Aliases for the column names we can use. WE created a list with our headers and then used the same.my_heads=['my_id','my_names','my_class','my_mark','my_gender']
df2.to_excel('C:\\data\\student2.xlsx',header=my_heads)startrow
Default value is 0, this is the top row.startcol
Default value is 0, this is the left most column.df2.to_excel('C:\\data\\student2.xlsx',startrow=3,startcol=2)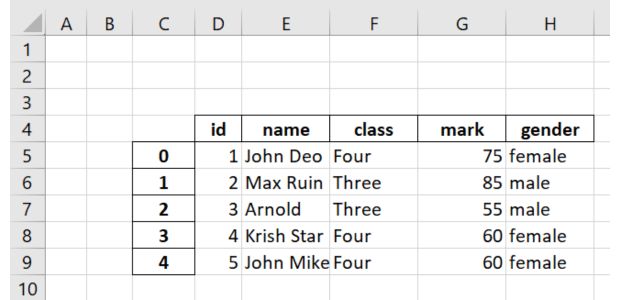
engine
We can use 'openpyxl' or 'xlsxwriter'freeze_panes
A tuple , one-based bottommost row and rightmost column that is to be frozen.df2.to_excel('C:\\data\\student2.xlsx',freeze_panes=(1,5))float_format
Formatting the floating point numbers.float_format="%.2f" will update the value 0.1234 to 0.12
Storing different worksheets
Excel has worksheets to store data in different sheets.When we create a new excel file the data stored in Sheet1. We can create different Sheets and store data in different worksheets.
By using sheet_name we can store in worksheet with specific name sheet_name='my_Sheet_1'
df.to_excel('D:\my_file.xlsx',index=False,sheet_name='my_Sheet_1')multiple worksheets
We will use one object of ExcelWriter to create multiple worksheets in a excel file.import pandas as pd
my_dict={
'NAME':['Ravi','Raju','Alex'],
'ID':[1,2,3],'MATH':[30,40,50],
'ENGLISH':[20,30,40]
}
df = pd.DataFrame(data=my_dict)
df2 = df.copy() # copy of df
with pd.ExcelWriter('D:my_file.xlsx') as my_excel_obj: #Object created
df.to_excel(my_excel_obj,sheet_name='my_Sheet_1')
df2.to_excel(my_excel_obj,sheet_name='my_Sheet_2')Appending worksheets
We will add two more worksheets to the existing files by opening the file in append mode.Note that we are using the same my_file.xlsx file created in above code.
We will be using mode='a' and engine='openpyxl' while creating the ExcelWriter object.
import pandas as pd
my_dict={
'NAME':['Ravi','Raju','Alex'],
'ID':[1,2,3],'MATH':[30,40,50],
'ENGLISH':[20,30,40]
}
df = pd.DataFrame(data=my_dict)
df2 = df.copy() # copy of df
with pd.ExcelWriter('D:my_file.xlsx',mode='a',engine='openpyxl') as my_excel_obj:
df.to_excel(my_excel_obj,sheet_name='my_Sheet_3')
df2.to_excel(my_excel_obj,sheet_name='my_Sheet_4')While executing the above code, you may get error saying Append mode is not supported with xlsxwriter. To solve this issue use engine='openpyxl' while creating the ExcelWriter object.
Data from MySQL table
We can read data from MySQL table and then store them in excel file.import mysql.connector
import pandas as pd
my_connect = mysql.connector.connect(
host="localhost",
user="userid",
passwd="password",
database="my_tutorial"
)
####### end of connection ####
sql="SELECT * FROM student "
df = pd.read_sql(sql,my_connect )
df.to_excel('D:\my_file.xlsx')Using SQLAlchemy MySQL connection
Read more on MySQL with SQLAlchemy connection. Below code will create student.xlsx file in the same directory, you can add path ( as above ) if you want the file to be created at different location.import pandas as pd
from sqlalchemy import create_engine
my_conn = create_engine("mysql+mysqldb://userid:pw@localhost/my_db")
sql="SELECT * FROM student "
df = pd.read_sql(sql,my_conn)
df.to_excel('D:\\my_data\\student.xlsx') # Add the pathimport pandas as pd
from sqlalchemy import create_engine
my_conn = create_engine("mysql+mysqldb://userid:pw@localhost/my_db")
sql="SELECT * FROM student WHERE class='Three'"
sql2="SELECT * FROM student WHERE class='Four'"
df=pd.read_sql(sql,my_conn) # class Three students
df2=pd.read_sql(sql2,my_conn) # class Four students
with pd.ExcelWriter('D:\\my_data\\student.xlsx',engine='openpyxl') as my_obj:
df.to_excel(my_obj,sheet_name='Three')
df2.to_excel(my_obj,sheet_name='Four')Storing part of the data
We can filter the DataFrame and then save the rows in xlsx file. For this we will use our test.csv file as we have more rows.Now let us store only two columns, class and name
import pandas as pd
df=pd.read_csv('test.csv')
df=df.loc[:,['class','name']]
df = pd.DataFrame(data=df)
df.to_excel('my_file.xlsx',index=False)Inserting DataFrame to google sheets
We can add our DataFrame to google sheets by using pygsheets library and google drive API.
Pandas DataFrame to Google sheet by set_dataframe
Pandas DataFrame to Google sheet by set_dataframe
Questions
- How do you export a Pandas DataFrame to an Excel file using the
to_excel()function? - What is the purpose of the
sheet_nameparameter in theto_excel()function? - Can you specify a custom name for the Excel file when using the
to_excel()function? - How can you exclude the index column from the exported Excel file using the
to_excel()function? - What additional optional parameters are available in the
to_excel()function to customize the Excel export? - How can you export only specific columns from a DataFrame to an Excel file using the
to_excel()function? - Is it possible to overwrite an existing Excel file when using the
to_excel()function? - How do you handle missing or empty values in the DataFrame while exporting to an Excel file?
- Can you export multiple DataFrames to separate sheets within the same Excel file using the
to_excel()function? - What file format does the
to_excel()function support for exporting DataFrames?
Data input and output from Pandas DataFrame Sample student DataFrame DataFrame to SQlite table at Colab platform using to_sql()
SQLite table to DataFrame at Colab platform using read_sql()
Pandas read_csv to_csv read_excel to_string()

Subhendu Mohapatra
Author
🎥 Join me live on YouTubePassionate about coding and teaching, I publish practical tutorials on PHP, Python, JavaScript, SQL, and web development. My goal is to make learning simple, engaging, and project‑oriented with real examples and source code.
Subscribe to our YouTube Channel here
This article is written by plus2net.com team.
https://www.plus2net.com

 Python Video Tutorials
Python Video Tutorials