Reading Data from Excel file using openpyxl
Download sample ( Excel file ) student.xlsx
Openpyxl library to read Excel file from cell or rows columns by using max min rows and columns
Opening Excel file for reading
from openpyxl import load_workbook
wb = load_workbook(
filename='D:\\student.xlsx',
read_only=True
) # change path
ws = wb['student'] # connecting to sheet
wb.close() # Close the workbook after readingReading a cell value
Here cell with row=2 and column=3 ( 1 - based index ) value is printed.from openpyxl import load_workbook
wb = load_workbook(
filename='D:\\student.xlsx',
read_only=True
)
ws = wb['student'] # connecting to sheet
print(ws.cell(2,3).value) # One particular cell value
wb.close() # Close the workbook after readingRow values
iter_rows(
min_row=None,
max_row=None,
min_col=None,
max_col=None,
values_only=False
)from openpyxl import load_workbook
wb = load_workbook('D:\\student.xlsx')
ws = wb['student']
# Iterate A1:C5 returning cell values only
for row in ws.iter_rows(min_row=1, max_row=5, min_col=1, max_col=3, values_only=True):
print(row)
wb.close()Returns a generator
If range is not given then it starts from A1
We will get ID ( first column ) and Name( second column ) values of five records including header row
for data in ws.iter_rows(
max_col=5,
max_row=5,
values_only=True
):
print(data[0],data[1]) # Show column 1,2 - id, namefor data in ws.iter_rows(
max_col=5,
max_row=5,
values_only=True
):
for d in range(len(data)):
print(data[d], end=' ') # print all data of a row
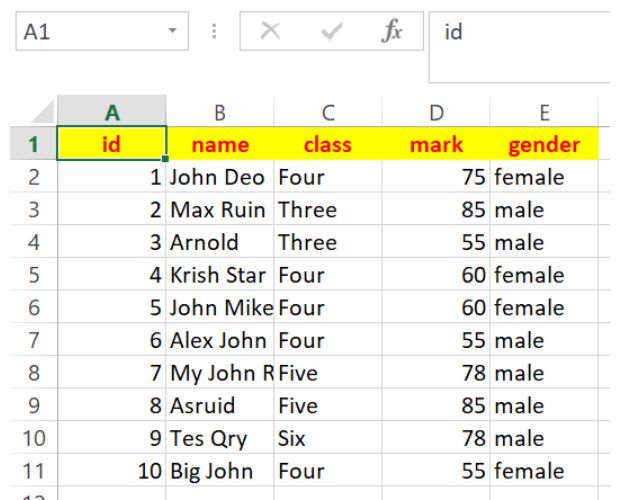
print('') # adding line breakid name class mark gender
1 John Deo Four 75 female
2 Max Ruin Three 85 male
3 Arnold Three 55 male
4 Krish Star Four 60 femalefor data in ws.iter_rows(
min_row=2,
max_col=5,
max_row=6,
values_only=True
):
for d in range(len(data)):
print(data[d], end=' ') # print all data of a row
print('') # adding line break at end of each row
1 John Deo Four 75 female
2 Max Ruin Three 85 male
3 Arnold Three 55 male
4 Krish Star Four 60 female
5 John Mike Four 60 femaleColumn values
ws.iter_cols(
min_col=None,
max_col=None,
min_row=None,
max_row=None,
values_only=False
)AttributeError: 'ReadOnlyWorksheet' object has no attribute 'iter_cols'
Change the mode.
wb = load_workbook(filename='D:\student.xlsx', read_only=False)for data in ws.iter_cols(
min_row=2,
min_col=2,
max_row=6,
max_col=2,
values_only=True
):
print(data)('John Deo', 'Max Ruin', 'Arnold', 'Krish Star', 'John Mike')min_row=2
for data in ws.iter_cols(min_col=2,max_row=6,max_col=2,values_only=True):
print(data)('name', 'John Deo', 'Max Ruin', 'Arnold', 'Krish Star', 'John Mike')Number of rows and columns
print(ws.max_column) # Max column count, output is 5
print(ws.max_row) # Max row count, output is 36Data of Last row
This can be used to generate next record id ( similar to auto incremented id column of MySQL database. )The first column data of last row is printed here.
print(ws.cell(ws.max_row, 1).value)Row with Maximum value
Show the row having highest mark in student table .More on isinstance()
max_mark = 0
row_with_max_mark = None
# Iterate through rows, skipping the header
for row in ws.iter_rows(min_row=2, values_only=True):
# Assuming 'mark' is the 4th column (index 3)
mark = row[3]
if isinstance(mark, (int, float)) and mark > max_mark:
max_mark = mark
row_with_max_mark = row
print("Row with maximum mark:")
print(row_with_max_mark)Getting average mark
total_marks = 0
count_marks = 0
# Iterate through rows, skipping the header
for row in ws.iter_rows(min_row=2, values_only=True):
# Assuming 'mark' is the 4th column (index 3)
mark = row[3]
if isinstance(mark, (int, float)):
total_marks += mark
count_marks += 1
if count_marks > 0:
average_mark = total_marks / count_marks
print("Average mark:", average_mark)
else:
print("No valid marks found to calculate the average.")
Download the above full source code from Github or run the code in your Google colab platform.
OpenPyxl Reading Excel file
https://github.com/plus2net/Python-basics/blob/main/openpyxl_2_reading.ipynb
OpenPyxl Reading Excel file
https://github.com/plus2net/Python-basics/blob/main/openpyxl_2_reading.ipynb
Read Excel Data Using Openpyxl in Python (Colab Demo)
openpyxl Library Database table to Excel file Managing Worksheets Styles and formatting Formulas
Excel data to Tkinter Treeview
SQlite to Excel using Pandas DataFrame Pandas DataFrame to Excel by to_excel()
Python Xlxwriter library

Subhendu Mohapatra
Author
🎥 Join me live on YouTubePassionate about coding and teaching, I publish practical tutorials on PHP, Python, JavaScript, SQL, and web development. My goal is to make learning simple, engaging, and project‑oriented with real examples and source code.
Subscribe to our YouTube Channel here
This article is written by plus2net.com team.
https://www.plus2net.com

 Python Video Tutorials
Python Video Tutorials