Projects using Pandas
";require "templates/body_start.php";?>Storing file name,modification time & size of dirctory in Excel file by using Pandas DataFrame G#01
Store file details against each directory in Excel file
- Create a list of directory to search
- Browse through each directory by using Path
- Create a blank DataFrame with one date column
- Check the file extension for required file types
- Collect size, modified date of each file
- Insert to dataframe against each file name
- Save the DataFrame with data in excel file.
- Loop through the next directory and repeat the above steps to store the file details.
import osfrom datetime import datetimeimport pandas as pd# source directory list to get list of filesl1=['javascript_tutorial','php_tutorial','html_tutorial','sql_tutorial','python']for d in l1: path = "C:\\xampp\\htdocs\\dir\\"+d+"\\" f_x='C:\\data2\\'+d+'.xlsx' #path with name, to store final excel file files=os.listdir(path) df = pd.DataFrame(columns = ['f_name', 'dt', 'size']) #create DF df['dt'] = pd.to_datetime(df['dt']) # change to date column for f in files: t_stamp=os.path.getmtime(path+f) # for file modificaton time #t_stamp=os.path.getctime(path) # for file Creation time f_name,f_extension=os.path.splitext(path+f) if(f_extension=='.php'): size=os.path.getsize(path+f) dt_mod = datetime.fromtimestamp(t_stamp) # date object #print('File Modified on:', dt_mod) # Prting date and time m_date = datetime.strftime(dt_mod, '%Y-%m-%d') # Change format #print(f, f_extension, m_date,size) df2 = pd.DataFrame({'f_name': [f], 'dt': [m_date],'size':[size]}) df=pd.concat([df,df2]) #df = df.append({'f_name' : f, 'dt' : m_date, 'size' : size},ignore_index = True) #print(df.head()) df.to_excel(f_x,index=False) # create excel file with file dataReport on modified files
Report from Excel file using Pandas DataFrame showing files modified using Date period G-02
Using above excel files we can read and generate report showing total files and modified files during a period. from datetime import datetimeimport pandas as pdl1=['javascript_tutorial','php_tutorial','html_tutorial','sql_tutorial','python']for d in l1: f_x='C:\\data\\'+d+'.xlsx' # path with file name df = pd.read_excel(f_x,index_col='f_name') df['dt'] = pd.to_datetime(df['dt']) # Total files - : - Number of files modified in year-month print(d,':-:',df.shape[0],':-:',len(df[df['dt'].dt.strftime('%Y-%m')=='2023-07'])) mask = (df['dt'] > '2023-7-1') & (df['dt'] <= '2023-8-10') print(d,':-:',df.shape[0],':-:',len(df.loc[mask]))Tkiner GUI to select directory and display result
Displaying Report on Tkinter window from Excel file using Pandas DataFrame G#03
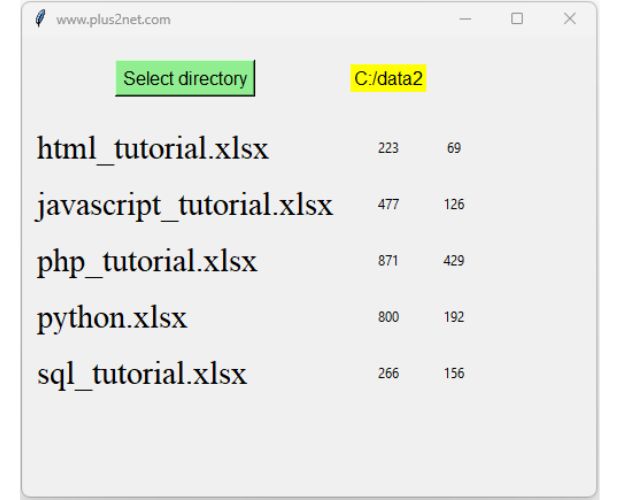
We can use one GUI Tkinter window with directory browsing to select the directory inside which our above Excel files are located. Using this directory we can collect all information from the excel file and display the result by using Labels.
import osfrom datetime import datetimeimport pandas as pdimport tkinter as tkfrom tkinter import filedialogmy_w = tk.Tk()my_w.geometry("500x400") # Size of the window my_w.title("www.plus2net.com") # titlefont1=('Times',22,'normal') # font family, size, styledef my_fun(): path = filedialog.askdirectory() # select directory lb1.config(text=path) # update the text of Label with directory path l1=os.listdir(path) # List of files in directory my_row=1 # Starting row number for d in l1: f_x=path+'//'+d # path with file name df = pd.read_excel(f_x,index_col='f_name') df['dt']=pd.to_datetime(df['dt']) #print(d,':-:',df.shape[0],':-:',len(df[df['dt'].dt.strftime('%Y')=='2023'])) my_label1=tk.Label(my_w,text=d,font=font1,anchor='w') my_label1.grid(row=my_row,column=0,sticky='w',padx=10,pady=5) my_label1=tk.Label(my_w,text=df.shape[0]) my_label1.grid(row=my_row,column=1,padx=10,pady=5) my_label1=tk.Label(my_w,text=len(df[df['dt'].dt.strftime('%Y')=='2023'])) my_label1.grid(row=my_row,column=2,padx=10,pady=5) my_row=my_row+1 # Go to Next row by adding 1 b1=tk.Button(my_w,text='Select directory',font=22, command=lambda:my_fun(),bg='lightgreen')b1.grid(row=0,column=0,padx=10,pady=20)lb1=tk.Label(my_w,text='',bg='yellow',font=18)lb1.grid(row=0,column=1,padx=2)my_w.mainloop() # Keep the window openFind out the orphan pages in a directory
A page without any links pointing to it is called an orphan page.In above code we have created Excel pages for each directory. We are going to use the same file to identify the pages without any incoming link or orphan pages.
Few points to Note.
- We are checking the files within the same directory. This script will not consider if any incomming link is there from other directory.
- This program will check for href links only so pages with JavaScript window or pages with FORM action attributes will also appear as orphan page.
import re,osimport pandas as pdl1=['php_tutorial'] # directory list to check for d in l1: f_x='D:\\data\\'+d+'.xlsx' # get the excel file for the file list df = pd.read_excel(f_x,index_col='f_name') f_list=list(df.index.values) path1='C:/xampp/htdocs/z~1234-plus2net/'+d+'/' # dir path file_list=os.listdir(path1) #print(len(f_list),f_list[1]) for file_name_to_check in f_list: #file_name_to_check='fast-loading-page.php' if(file_name_to_check in file_list): f_link=True #print('File is there, checking') for f in file_list: if(os.path.getsize(path1+f)>500): filename,file_extension=os.path.splitext(path1+f) if(file_extension=='.php'): # check this extension only fob= open(path1+f,'r',encoding='utf8',errors='ignore') data=fob.read() # collect data fob.close() # close file object urls1 = re.findall(r'href=[\'"]?([^\'" >]+)', data) # list of URLs if(file_name_to_check in urls1): f_link=False break if(f_link): print(file_name_to_check) else: print('File is not there, check the list. ',file_name_to_check)